
Let’s begin with the name: Cosmos…a word that conjures thoughts of something complex, yet orderly; individual, yet part of a system; different, yet known.
Today’s applications must be highly responsive and always online. To achieve low latency and high availability, instances of these applications need to be deployed in data centers that are close to their users. Applications need to respond in real-time to large changes in usage at peak hours, store ever increasing volumes of data, and make this data available to users in milliseconds.
To achieve such robustness, Microsoft Azure has come up with a globally distributed, multi-model database service called Cosmos DB.
There are a number of benefits, which include:
- 24/7 availability
- Elastic scalability of throughput and storage, worldwide
- Guaranteed low latency at 99th percentile, worldwide
- Precisely defined, multiple consistency choices
- No schema or index management
- Widely available
- Secure by default and enterprise ready
- Significant savings
- …and the list goes on.
However, Cosmos DB does have a limitation with respect to autoscaling. It can only scale down to 10 % of the maximum throughput set by the user. Hence, this can hinder cost optimization.
By the way is autoscaling now enabled at cosmos DB.
Or we can point in this blog that we implemented a autoscaling since not available and we will post in another post.
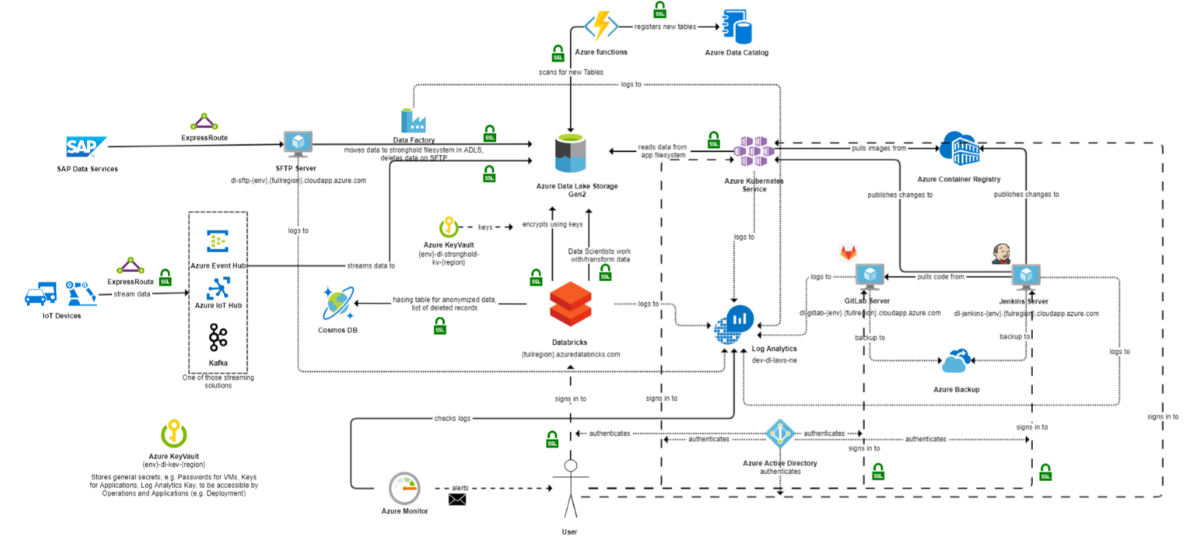
Figure 1: Data Lake architecture in Microsoft Azure
To understand this better, let us have a look at the above use-case. It explains the relationship between a number of data lake services, and their interactions.
- First the data is ingested to the cloud through innumerable sources.
- The Data is then pushed into Stronghold in ADLS through Data-factory.
- Data-factory runs a Databricks notebook, which encrypts the data.
- The encrypted data is then written to the raw folder. The hash table is then updated to the Cosmos DB.
- An Azure function scans the folder for any new ingestion, and registers it into the Data Catalog.
- A Data Scientist signs in to Databricks using their AD credentials. They can then work with the raw data, transform it as desired, and put it into the APP folder.
- The data in the APP folder can be used and analyzed. The code is then pushed into the Git Lab on cloud.
- Jenkins, which is also running on the cloud, builds the new code, packages it into a container, and pushes the container into the Azure Container Registry.
- Jenkins updates the deployment in Azure Kubernetes Service, which in turn pulls the new container image from the Azure Container Registry.
- Log Analytics updates the log information from the resources running on cloud.
- There are also monitoring alerts available that notify operation teams against any configured alerts.
Four our purposes, the fourth point is the most pertinent, since it deals with an interaction with Cosmos DB. Basically, two different containers of Cosmos DB were used: namely the Hashing container and the Anonymization container.
Inside the Hashing container of Cosmos DB
It contains hashed BPID keys and encrypted field values ingested into Cosmos DB. The data ingested was verified first with keys that were already available in Cosmos DB (which required a read operation before a write operation).
Inside the Anonymization container of Cosmos DB
This collection was used to check if something has been already deleted.
The data of around 2 million customers was ingested in Cosmos DB. In order to attain optimum performance it was necessary to maintain a system in which the thoroughput could be increased before the reading starts, and decreased after successful completion of the reading. As explained earlier, this is the part where we check the customer records available on Cosmos DB before pushing a new one.
This is because reading 2 million records will take around 7–10 minutes, which is much too long. Leaving records to process in such a manner is not optimal in all cases, since the records number is inconsistent, and can increase or decrease in the short-term.
Azure Cosmos DB allows us to set provisioned throughput on databases and containers. There are two types of provisioned throughput: standard (manual), and auto scale. In Azure Cosmos DB, provisioned throughput is measured in terms of request units/second (RUs). RUs measure the cost of both read and write operations against your Cosmos DB container, as shown in the following image:

The throughput provisioned for a container is evenly distributed among its physical partitions, and, assuming a good partition key (one that distributes the logical partitions evenly among the physical partitions) the throughput is also distributed evenly across all logical partitions of the container. One cannot selectively specify the throughput for logical partitions. This is because one or more logical partitions of a container can be hosted by a physical partition, and the physical partitions belong exclusively to the container (and support the throughput provisioned on the container).
If the workload running on a logical partition consumes more than the throughput allocated to the underlying physical partition, it’s possible that your operations will be rate-limited. What is known as a hot partition occurs when one logical partition has disproportionately more requests than other partition key values.
When rate-limiting occurs, one can either increase the provisioned throughput for the entire container or retry the operations. One should also ensure a choice of partition key that evenly distributes storage and request volumes.
The following image shows how a physical partition hosts one or more logical partitions of a container:
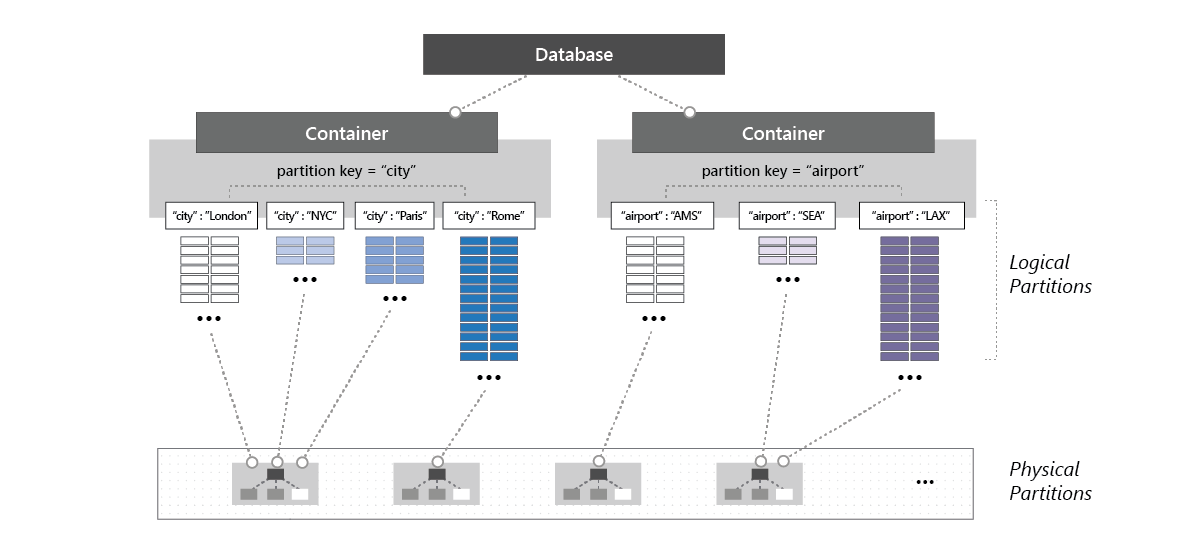
The problem here is that defining throughput must be done manually, and even if one selects the autoscaling option, this simply scales the throughput between the assigned throughput and 10% of this value. The minimum throughput cannot be achieved directly which may not be that cost-effective.
The reason for this is related to the parallelization of reading achieved by logical partitions. These logical partitions are completely managed by Cosmos DB, and cannot be influenced, which means the number of logical partitions remain the same no matter how we try to play around with the partition key. For example, a partition key (i.e. a random number between 0 and 32) was used to see the impact on the number of logical partitions, but resulted in the same number: 4.
Reading in parallel from Cosmos DB is about 7–10 minutes with one executor on each partition, and with the throughput being equally shared between the partitions. A throughput of 4000 RU means that each partition should get around 1000 RU. On the high-end, the throughput value can be set to any number. This means that we can us-scale as much as necessary to make computations faster, but on the low-end the throughput value will still be set to 400 RU.
Now, one might think that a minimum of 400 RU should be fine, and that we just need to concentrate on the high-end where the most significant performance gains can be made. But this is not how Microsoft tools work. You see, down-scaling is also not completely independent, and instead depends on the data volume. On top of this, down-scaling is as crucial as up-scaling: it saves huge amounts of money by reducing the expense on under utilized resources
The best solution, at least for the above implementation, was not especially complicated. It was simply conscious optimization applied using common sense. A small code snippet was executed on the spark cluster. The job of this code was to check if the minimum value (that being 400 RU) is accepted or not. Should this value not be accepted, then an ERROR is thrown, and its value is increased by 100 RU. This continues until an optimized down-scaling parameter is finally accepted. Of course, the code takes into account the data volume. For up-scaling, no such problem was encountered, and hence no work-around was required.
So, how did Microsoft Azure perform when tested with 2 million records?
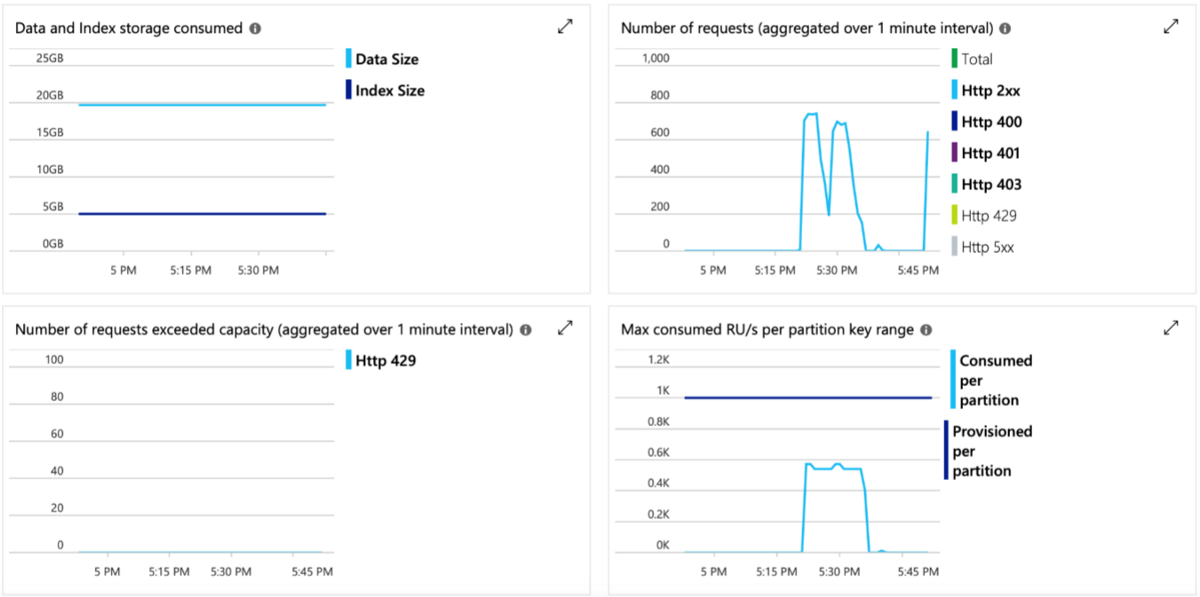
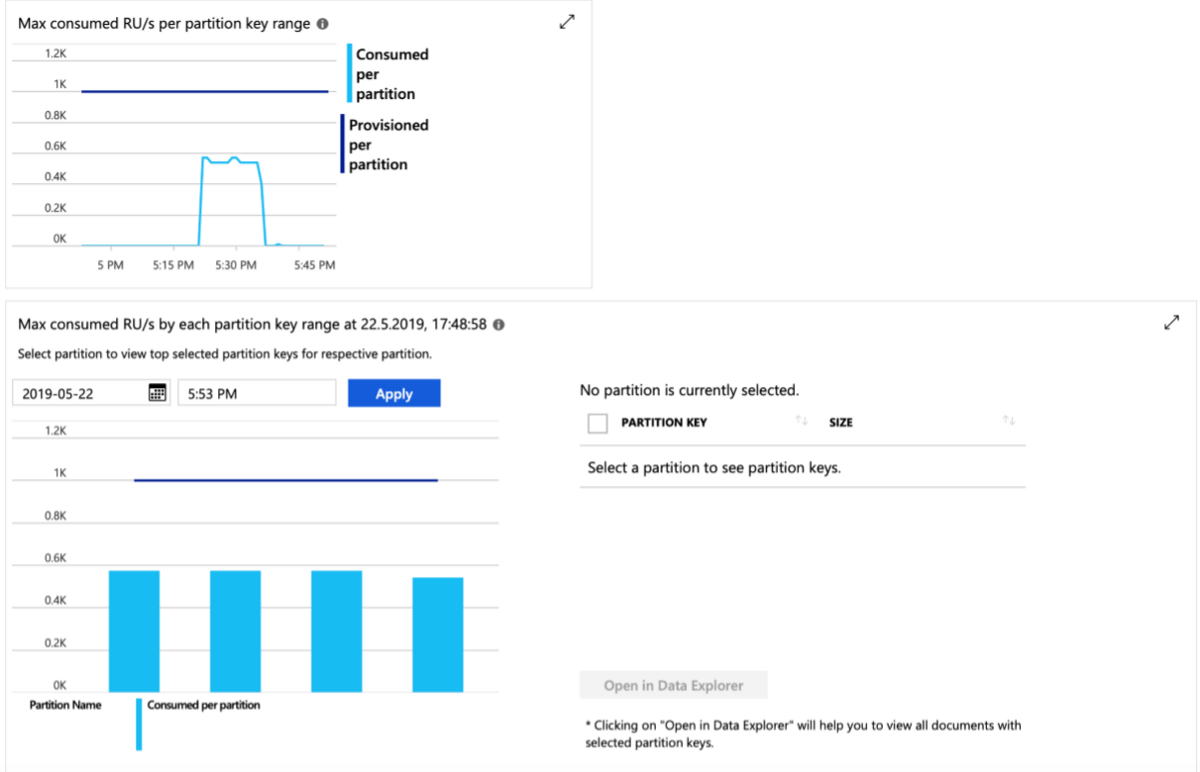
I personally think that, seeing as our solution required field-level data encryption and providing role-based access to the database, PostgreSQL or Microsoft SQL could have been good alternatives. From a complexity point of view, PostgreSQL or Microsoft SQL are simple in terms of writing queries on unencrypted data. But since a data storage API for workflows was required to write back to legacy systems, Cosmos DB showed more potential at the key level in terms of being a robust database.
Thank you for reading. I hope this blog opened doors to new solutions. Ciao…
Acronym:
- CISO : A chief information security officer
- Cosmos DB : A key-value pair database from Azure
- RU: request Unit
- ADLS: Azure Data Lake Storage
- BPID:Business process id
- LKP: Look up table

