
Introduction
Cloud computing has become a popular option for many businesses in the European Union. As of 2021, 42% of EU businesses are using cloud computing services, and most of the companies are using cloud databases, CRM applications, and other advanced cloud services (source: Eurostat).
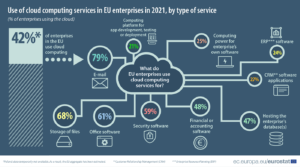
Figure 1. Use of cloud computing services in EU enterprises in 2021 (source: Eurostat)
Why host Ab Initio data applications in a cloud?
Using a container orchestration platform for hosting Ab Initio data applications in a cloud provides several advantages, such as efficient resource utilization, automated scaling, and simplified management of containerized applications. With features like load balancing, service discovery, and automated rollouts, container orchestration platforms like Kubernetes and Docker are essential tools for organizations looking to maximize the benefits of cloud computing.
The key decision driver for hosting Ab Initio data applications in the cloud is whether your data sources or targets are in the cloud. Typical use cases for hosting Ab Initio data applications in the cloud include:
- processing data in cloud-based databases (like Snowflake, Amazon DynamoDB and others), cloud-based file or object storages (e.g. Amazon S3)
- migrating your current on-premise data warehouse solution to pure-cloud or hybrid-cloud solution.
Why Use a Container Orchestration Platform?
No matter whether you host your Ab Initio applications on-premise or in a cloud, most probably you’re paying for idle compute resources since your Ab Initio applications consume the resources only when you execute jobs. At the same time your teams may compete for server resources since they cannot share the same infrastructure simultaneously.
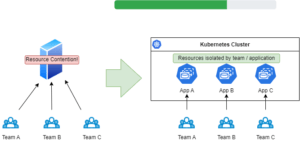
Hosting Ab Initio data applications in a container orchestration platform may become increasingly popular due to its numerous benefits, including increased scalability, portability, and ease of deployment. Rolling out your Ab Initio application to the Kubernetes cluster may solve these problems.
First, you can put the exact amount of computing resources and storage you need to run it in your application specification.
Second, you can create as many isolated applications as you need for multiple teams – e.g., test teams may consume the same test data sources. Still, they need to test several applications independently of each other.
Third, with elastic resources, you consume only the resources at the time of testing – major cloud providers support automatic scaling of computing resources. So, you can horizontally grow your application within specified boundaries – for instance, set up the auto-scaling nodes group up to 5 worker nodes. Kubernetes will scale out the applications across worker nodes up to the available limit when needed. Once your tests are complete, Kubernetes will automatically scale in the worker nodes.
New environment setup is usually a sophisticated task – you must prepare the infrastructure, install all components, configure parameters, and wire up the environment’s data sources and targets. Even if you have an automated solution, configuring it is always a big challenge. Containerization solves these issues – when you design the image of Ab Initio data application, you must specify the whole stack of software required to run your application (OS, Co>Operating System, third-party libraries), including environment-independent parameters and configuration files.
During Kubernetes-application design and environment-specific configuration steps, you finalize this work – your application gets the uniform image binary and environment-specific configurations (e.g. wiring with all required databases, directories, etc.).
Application deployment on test and production environments is much more consistent in Kubernetes – the application packaging is unified across all environments and contains all required components, and configuration elements are decoupled from the application image.
From legacy to containers
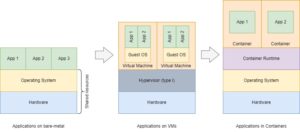
In the traditional deployment era, we used to run applications on bare-metal servers. It has one notable advantage – a simplicity of application maintenance, but several disadvantages:
-
Lack of resources segregation – memory leak in App 1 may cause all other applications to freeze;
-
Lack of resiliency – you needed to take care of app crashes
-
Lack of seamless upgrade – usually, you need to stop the current application before an upgrade
Nowadays, the reliability of customer-facing applications is one of the key drivers of a successful company. This is especially important for online applications – from real-estate search engines to sophisticated e-commerce solutions and online banking applications.
The next era began with evolving of hypervisors (both types I and II), which allowed “to slice” physical server’s resources between different virtual machines and run applications. The main advantage gained was the separation of resources. Each application or a set of applications were running in isolated virtual machines with limited resources. But this advantage comes at a cost – each VM requires an operating system, which creates an overhead of required computing resources.
The container era tried to overcome all mentioned disadvantages. The containers concept is based on container runtime, which allows running applications in isolated containers reusing the resources of underlying OS – from disk to kernel OS functions. Also, it brings the same advantage of resource constraints based on the Linux-kernel cgroups feature.
Kubernetes brought additional features to make deployments and maintenance of containerized applications easier:
-
Horizontal scaling – Kubernetes allows you to configure your application to run in parallel in a required number of containers. Ab Initio supports this paradigm, including data parallelism;
-
Seamless upgrades – no-downtime deployments with rolling upgrades or more sophisticated blue-green and canary deployments;
-
Service discovery and load balancing – allows auto-discover services and evenly distribute the workload across the cluster.
-
Self-healing – if your application crashes, Kubernetes will try to restart it automatically.
Containerized Ab Initio application
Can we containerize Ab Initio applications?
The short answer is yes, we can, and we recommend going for it wherever it’s possible:
-
Use the containerized applications to run both Ab Initio web applications (like Control Center, Authorization Gateway, Query>It, etc.) and Co>Operating System which is the heart of data applications.
-
Ab Initio provides great features to bring elastic scalability to your data applications in Kubernetes clusters. It also supports all major cloud providers both for online and batch data processing.
How to containerize Ab Initio data application?
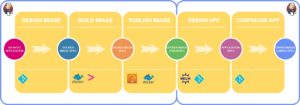
To containerize Ab Initio data applications, follow these five major steps:
-
Design image – prepare your Ab Initio application package to run in containers
-
Build image – assemble the application image with all run-time dependencies
-
Publish image – publish the image to private image registry
-
Design Kubernetes-application – prepare the environment-specific configuration of your application
-
Configure application – prepare the environment-specific configuration of your application
In most use cases, you will need an automated Continuous Integration process and tools to perform these steps above as soon as your data applications are growing rapidly. We distinguish two loose-coupled flows of this process:
-
Continuous Integration of Ab Initio application Docker-image
-
Continuous Integration of Kubernetes application and environment-specific configuration
Design Docker-image
Design an Ab Initio data application image specification so that it is runnable inside a container runtime environment:
-
Include all run-time dependencies (e.g. Co>Operating system, database drivers, JRE, etc.);
-
Separate configuration from the app image – you need to avoid environment-specific configurations inside the application image;
-
Optimize the structure of your image so that it contains a minimal number of layers with maximum caching in mind.
As a result, you’ll get an application image specification that can then be used at the build stage.
Build image
This means assembling the application image according to a specification – usually on some dedicated build host. We prefer using Docker to build the images as an enterprise standard, but you can choose from various available options like containerd, Kaniko, and others.
As an output, you’ll get an application image stored in the local Docker registry on a build host.
Publish image
Once your image is ready, you need to publish it to some Docker-image private registry (like Amazon ECR) accessible by your Kubernetes cluster. At this step, we also recommend performing the automatic security scan (at least for major changes).
Design Kubernetes-application
With the previous stage, you can run your application in any container runtime (Docker, containerd and others), but to get most of the benefits, you need to design an application configuration to run it using Kubernetes as an orchestration system. We recommend using package managers (like Helm) to simplify the design and further roll-out / roll-back operations of Kubernetes applications.
Configure Kubernetes-application
Setup of configuration elements of your application is decoupled from the application image design and even from Kubernetes-application design process:
-
It should reflect the target environment setup – i.e., data volume mounts, database connection strings, secrets, and other environment-specific parameters of the Ab Initio application.
-
It should also contain all required configuration files if your application design requires them.
We recommend putting all configuration elements under a source-control system to enable the versioning and release management process to run easier.
How to deploy your Ab Initio application?
The deployment process is usually automated in the CD pipeline, and we recognize several steps:
-
Choose the target environment – Kubernetes cluster
-
Deploy your application to the target Kubernetes together with environment-specific setup, i.e., connections to specific databases, file paths, credentials, etc..
-
In SIT environment, we also run automated integration and regression tests as part of the deployment pipeline.
-
Quality gateway checks – if the quality criteria pass, then report the deployment success; otherwise, roll back the deployment.
Further insights
Using Kubernetes as an orchestration system implies that your Ab Initio application design respects important topics:
-
Security – design your applications so that they apply the best security practices for Kubernetes applications.
-
Data parallelism – avoid using the standard approach with a multi-file system since data parallelism is supported differently within the Kubernetes cluster.
-
File operations – use cloud storage, like S3 object store, or consider persistent volumes if you want to retain your data if your app dies during an incident.

