
How rigorous testing ensures systems withstand real-world pressures, featuring a deep dive into Ab Initio implementations.
Introduction
Often overlooked, or the first to be cut as deadlines approach (an all too common occurrence unfortunately), testing is one of the most important parts of the software lifecycle helping to ensure quality and adherence to the requirements.
From unit, acceptance, integration and system testing, today we are going to look at a form of performance related testing taken from a real world implementation using Ab Initio.
Stress Testing
What is it
Stress testing is a method of pushing an intervals worth of data (for example, an hour, or a day) through a running system, but at a higher throughput than in the real production environment, and in some sectors, for example finance, can be a regulatory requirement.
Running production data through QA, or development environments has implications for GDPR, it may not be appropriate, or legal to copy that data to test or development teams without having sensitive data first masked or simulated. Whilst this is an important consideration and topic in and of itself, in this post we are demonstrating the mechanism for stress testing so we will assume that such masking of data has already been performed.
It provides the ability to push an interval’s worth of data (number of hours, a whole day) through a system at double, triple or higher rates, but it also does not preclude running the data through at the original rate to simulate a full time interval.
The intention then, is to demonstrate that the system can handle unusual load levels without failure or producing the incorrect responses.
The problems that must be solved include
- Capturing the data
- Replaying the data in the original order sequence but at a higher rate
- Recording and comparing the two runs
Background
The system under stress testing in this example is a continuous system, processing incoming reference data and market depth (multiple levels of bid and ask prices and quantities of each), this data contains a mixture of high frequency updates (market data) and low frequency updates (sanctioned and permitted instruments).
This data must be maintained at the same time as processing requests for prices throughout the day based on the instantaneous values of the market depth.
The system has to respond to requests in under 500ms under various load conditions, with a regulatory requirement for be able to do so accurately and consistently at double and triple the normal input rates across a whole day.
In order to replay a time period’s worth of data (a number of hours, a whole day) and still produce the same responses, the market depth data must be available at the corresponding time that it was available in the original run.
Below is an overview of the system under stress testing:
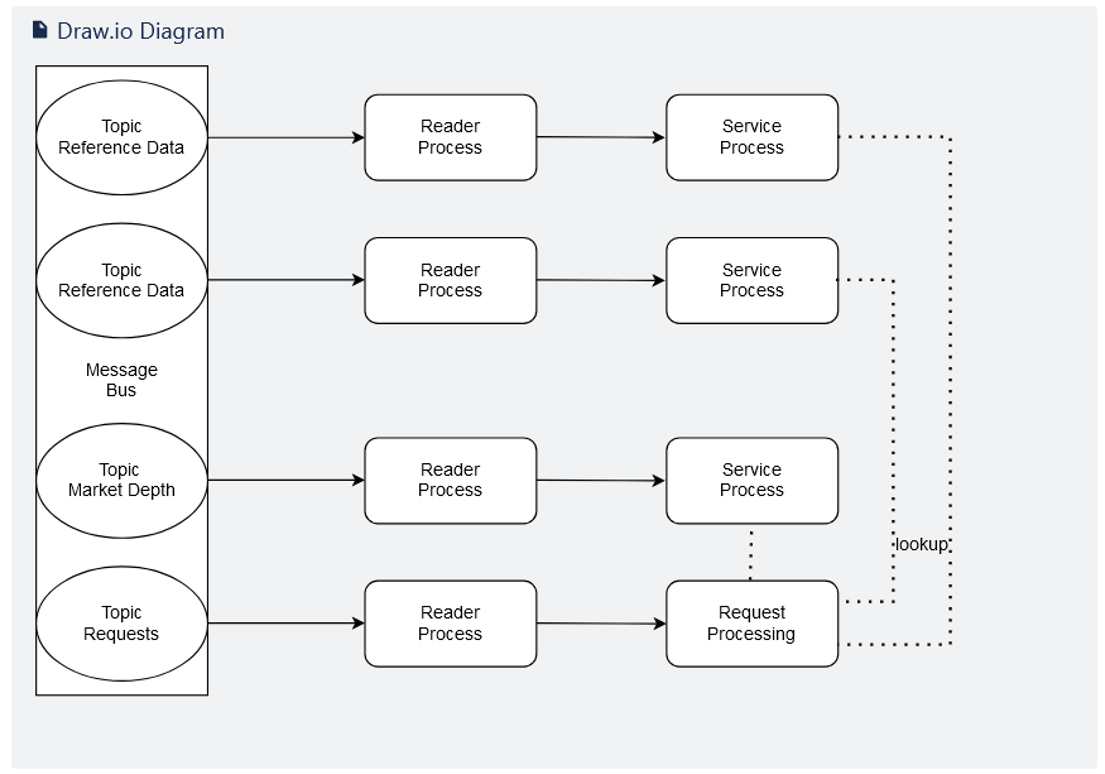
Here we can see that each topic from the message bus is served by a single reader process.
A message bus is a 1-to-many model of distribution. The destination in this model is usually called topic or subject. In the above diagram each topic is a separate stream of data.
A reader process is a piece of code that can read a topic and process the messages it receives into a format suitable to be processed by a server process.
A server process is a piece of code that can receive messages and, in this case, store the contents of those messages in a form that can be used for later retrieval by the request processing component of the diagram above.
Each reader process will send its data to an associated service process. Each service process is storing, modifying or updating either reference data, market depth or processing requests.
We need to be able to maintain the exact arrive time of each message across all topics so that during the stress testing each message is replayed in the original time sequence order, even if at faster rates.
Implementation
Capturing the Data
As each message from each topic is read by its reader process, that process can optionally persist a copy of the data along with a timestamp. As this can generate very large data sets, the option to write such files is turned off by default, it can be switched on by setting a simple flag, even whilst the process is running. Writing the files to disk whilst the process is running does not impact the performance due to the parallel processing nature of the processes.
The result of setting the flag, is to create one data file per topic, containing data for the period of time that the flag is active. Clearing the flag stops the recording of data.
In this Ab Initio implementation, all the reader processes are a single graph. Each reader process is configured using Ab Initio’s parameter sets (psets).
Converting the Data flow to higher rates
The data for each topic has been recorded into a series of files, one per topic. Each record in each file, also contains a timestamp of when that message was received.
What is required now, is a twostep process:
- corral all the data from all the recorded data files, into a single file sorted on the timestamp so that we are able to recreate the exact sequence of messages as they occurred in real time across all the topics.
- calculate the time gap between each message.
Once we have the messages and the gap information, we can change the gap, halving the gap for instance, doubles the throughput of each message. Using this, it´s now a simple matter to generate data files for different throughput levels.
Replaying the Data
We´ve now created a number of data files, each containing data for the whole test period for all messages in correct time order and a calculated gap between each message providing the higher rate throughput.
All we need to do now is read that data file, maintaining the calculated gap between each message and publish those messages to the appropriate service process. This single publishing process will publish each message to the appropriate service at the required time intervals.
We´ve now created a number of data files, each containing data for the whole test period for all messages in correct time order and a calculated gap between each message providing the higher rate throughput.
All we need to do now is read that data file, maintaining the calculated gap between each message and publish those messages to the appropriate service process. This single publishing process will publish each message to the appropriate service at the required time intervals.
Recording and Comparing the Data
Whilst all the code in the system is being tested at the higher throughput, in this example, it is the output of the request processing code that is of most interest. We need the output of this code taken at the time the data was originally recorded to use as our baseline for the stress testing at higher rates. This can be recorded at the time the input data was recorded, using the same flag mechanism.
However, this means having code in production whose only purpose is to record stress test data and that may not be appropriate for performance reasons. The alternative then is to first run the stress test data using the original timings and then recording the code output to use as the baseline. The test can then be repeated at higher throughput rates to compare against the baseline.
Conclusion
Stress testing provides a means of performance testing under heavier than normal loads using actual data from either the QA test environment or from production data (with suitable considerations to GDPR). In some sectors such as finance this kind of testing is a regulatory requirement. It is designed to be used in continuous real time processing environments.
This stress testing design pattern can be incorporated into a wide range of real and near real tie systems, and we at synvert Data Insights would be happy to provide a more in-depth demonstration or provide assistance in your implementation.

